


Inteligentný reproduktor nachádzajúci sa teraz v obývacej izbe mnohých domácností je príkladom pokročilej UI v akcii v každodennom živote prostredníctvom schopnosti rozpoznať prirodzený jazyk a syntetizovať vysoko kvalitné hovorené slovo. Aby to reproduktor dokázal, musí preniesť dáta na viacero vysokorýchlostných počítačov vo vzdialených serverovniach. Zabudovaný hardvér sa považuje za príliš obmedzený na to, aby mohol spustiť typy algoritmov neurónovej siete s hĺbkovým učením (Deep Neural Networks – DNN), ktoré sú na to potrebné.
Aplikácie UI
UI sa nemusí obmedziť na nasadenie len v rámci vysoko výkonných počítačov nachádzajúcich sa v serverovniach. Ukazuje sa, že technológia UI sa môže uplatniť ako spôsob riadenia nesmierne zložitého protokolu 5G New Radio. Počet parametrov kanálov, ktoré treba analyzovať pomocou slúchadiel na dosiahnutie optimálnych dátových rýchlostí, prekonal schopnosť technikov vyvinúť účinné algoritmy. Algoritmy naučené na základe údajov získaných počas prevádzkových testov poskytujú spôsob, ako efektívnejšie vyvážiť kompromisy medzi rôznymi nastaveniami.
Pokiaľ ide o zabezpečenie a udržanie správnej činnosti priemyselných zariadení pracujúcich vo vzdialených prevádzkach, algoritmy strojového učenia, ktoré bežia na zabudovanom hardvéri, môžu byť tou správnou voľbou. Tradičné algoritmy, ako napríklad Kalmanove filtre, sa zaoberajú lineárnymi vzťahmi medzi rôznymi typmi vstupných údajov, ako sú tlak, teplota a vibrácie. Avšak včasné varovania pred problémami často vychádzajú zo zmien takýchto vzťahov, ktoré môžu byť veľmi nelineárne.
Implementácia UI
Systémy môžu byť naučené na základe údajov zo zdravých a nefunkčných strojov, aby zistili potenciálne problémy pri spracúvaní údajov v reálnom čase. Avšak neurónová sieť, aj keď dnes je obľúbenou voľbou, nie je jediným dostupným riešením UI. Existuje veľa algoritmov, ktoré možno použiť a alternatívne riešenie môže byť najvhodnejšie pre danú úlohu.
Jedno riešenie možno nájsť v UI založenej na pravidlách. UI je v tomto prípade postavená skôr na odborných znalostiach odborníkov v danej oblasti ako na priamom strojovom učení. Znalosti odborníkov sa zakódujú do databázy konkrétnych pravidiel. Hlavný procesor analyzuje údaje v súlade s pravidlami a pokúša sa nájsť najlepšiu zhodu s podmienkami, s ktorými sa stretáva. Systém založený na pravidlách má nízke výpočtové náklady, ale vývojári musia riešiť výzvy, ak sa vzniknuté podmienky dajú ťažko vyjadriť pomocou jednoduchých vyhlásení alebo ak vzájomné vzťahy medzi vstupnými údajmi a akciami neboli správne pochopené. Jedným z posledných príkladov, kde strojové učenie excelovalo, je rozpoznávanie reči a obrazu.
Strojové učenie je úzko spojené s procesmi optimalizácie. Na základe prvkov vstupnej databázy sa algoritmus strojového učenia pokúsi nájsť najvhodnejší spôsob ich klasifikácie alebo usporiadania. Algoritmus usporiadania kriviek založený na technike, ako je lineárna regresia, možno považovať za najjednoduchší možný algoritmus strojového učenia: používa dátové body na formulovanie najvhodnejšieho polynómu, ktorý sa potom môže použiť na určenie najpravdepodobnejšieho výstupu pre daný vstupný vzťažný bod. Uvedený prístup je vhodný len pre systémy s veľmi malými rozmermi. Skutočné aplikácie strojového učenia sa môžu zaoberať komplexnými, rozsiahlymi údajmi.
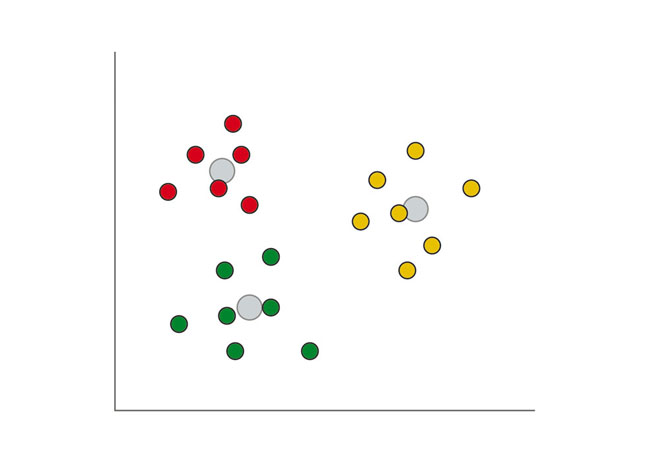
Klastrovanie ide ešte ďalej za klasifikáciu údajov do skupín. Typický algoritmus je založený na metóde ťažísk, ale v strojovom učení sa používa mnoho ďalších typov klastrovej analýzy. Systém založený na ťažiskách používa geometrickú vzdialenosť medzi dátovými bodmi na určenie toho, či spadajú do jednej alebo druhej skupiny. Analýza klastrov je často iteračný proces, v ktorom sa uplatňujú rôzne kritériá na určenie toho, kde sa tvoria hranice medzi klastrami a ako blízko musia byť súvisiace dátové body v rámci jedného klastra. Táto technika je však efektívna pri rozpoznaní vzorov v rámci údajov, ktoré by mohli odborníkom v danej oblasti uniknúť. Ďalšou možnosťou na rozdelenie údajov do tried je podporný vektorový stroj (SVM), ktorý rozdeľuje viacrozmerné dáta do tried pozdĺž nadrovín vytvorených pomocou optimalizačných techník.
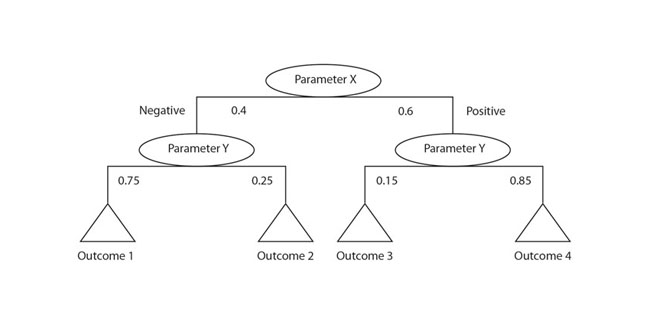
Rozhodovací strom poskytuje spôsoby použitia klastrovaných údajov v základni pravidiel. Ukazuje, ako algoritmus UI spracúva vstupné údaje, aby vytvoril odpovede. Každá vetva v strome môže byť určená klastrovou analýzou vstupných dát. Napríklad, systém sa môže správať odlišne pri určitej teplote, pričom nameraný tlak, ktorý je prijateľný pri iných podmienkach, môže indikovať problém. Strom rozhodovania môže použiť tieto kombinácie podmienok na nájdenie súboru pravidiel najvhodnejšieho pre danú situáciu.
Hoci DNN vyžadujú pri svojej činnosti v reálnom čase vo všeobecnosti vysokovýkonný hardvér, existujú aj jednoduchšie štruktúry, ako napríklad diskriminatívne neurónové siete (adversarial neural networks), ktoré boli úspešne implementované v mobilných robotoch založených na 32- alebo 64-bitových procesoroch, ktoré sa napr. nachádzajú v platformách Raspberry Pi. Kľúčovou výhodou DNN je veľký počet vrstiev, ktoré používa. Vrstvená štruktúra umožňuje neurónom zakódovať spojenia medzi viacrozmernými dátovými prvkami, ktoré môžu byť zásadne oddelené v priestore a čase, ale ktorých dôležité vzťahy sú odhalené počas procesu učenia.
Okrem režijných nákladov na zabezpečenie výpočtového výkonu je ďalšou nevýhodou DNN to, že potrebuje obrovské množstvo údajov na jej naučenie. Výskumníci z oblasti UI práve preto v súčasnosti skúmajú iné možnosti, ako sú napr. algoritmy založené na Gaussovských procesoch. Tie využívajú pravdepodobnostnú analýzu údajov na vytvorenie modelov, ktoré fungujú podobne ako neurónové siete, ale využívajú oveľa menej údajov na svoje naučenie. Z krátkodobého hľadiska je však úspech DNN kľúčovým kandidátom na riešenie zložitých viacrozmerných vstupov, ako sú obrazové, video a streamingové vzorky zvukových alebo prevádzkových údajov.
Jednou z možností v aplikáciách so zložitými požiadavkami môže byť použitie jednoduchého algoritmu UI v zabudovanom zariadení na hľadanie súvislostí vo vstupných dátach a následne požiadanie o služby z cloudu, ktoré by podrobnejšie prezreli údaje a poskytli presnejšiu odpoveď. Takéto delenie by pomohlo udržať výkon v reálnom čase, obmedziť množstvo dát, ktoré treba prenášať na dlhé vzdialenosti, a zabezpečiť nepretržitú prevádzku aj pri dočasných výpadkoch siete. Ak dôjde k strate spojenia, zabudovaný systém môže ukladať podozrivé údaje do rýchlej vyrovnávacej pamäte, kým sa neobnoví spojenie so službami v cloude.
Poskytovatelia UI
Amazon Web Services (AWS) a IBM patria medzi spoločnosti, ktoré už dnes ponúkajú svojim zákazníkom služby UI využívajúce cloud. AWS poskytuje prístup k širokej škále hardvérových platforiem vhodných na strojové učenie vrátane univerzálnych serverovní, akcelerátorov GPU a polí FPGA. DNN bežiacu v cloude možno vytvoriť pomocou rámcov s otvorenou architektúrou, ako sú Caffe a Tensorflow, ktoré dnes široko využívajú používatelia UI.
Spoločnosť IBM vytvorila priame rozhrania k platforme Watson UI na doskách, ako je Raspberry Pi, čo uľahčuje tvorbu aplikácií strojového učenia pred tým, ako sa zaviaže k finálnej architektúre. ARM poskytuje podobné prepojenie so spoločnosťou Watson prostredníctvom platformy Mbed postavenej na internete vecí.
Napriek tomu, že sa UI môže javiť ako nová hranica v oblasti výpočtovej techniky, existencia vysokovýkonných, cenovo dostupných dosiek, ako je Raspberry Pi, a prístup k službám strojového učenia využívajúceho cloudové technológie znamená, že vývojári zabudovaných systémov majú jednoduchý prístup k celému spektru algoritmov strojového učenia, ktoré boli objavené počas posledných niekoľkých desaťročí. Vzhľadom na to, že sa vyvíjajú sofistikovanejšie techniky, kombinácia spracovania priamo na doske a cloudových výpočtov zabezpečí, že vývojári zabudovaných systémov s nimi budú môcť zostať v kontakte a poskytovať čo najchytrejšie riešenia.
Cliff Ortmeyer
globálny riaditeľ technického a komerčného marketingu
Premier Farnell
https://uk.farnell.com/
https://sk.farnell.com/
