


Spracovanie senzorických dát s cieľom získavania znalostí
Slovné spojenie big data je známe veľmi pravdepodobne už aj laickej verejnosti. Práve kontinuálne monitorovanie stavu rôznych systémov počas ich činnosti či akcií používateľov a rôznych udalostí generuje za pomerne krátky čas obrovské objemy dát, z ktorých možno neskôr riešiť úlohy prediktívneho dolovania. Použitím metód strojového učenia sa generuje prediktívny model, ktorého nasadenie v praxi znamená naučiť systém alebo podporný systém reagovať na udalosti získané z jeho vlastnej prevádzky relatívne autonómne. Druhou častou možnosťou je ponúknuť operátorovi tzv. systém na podporu rozhodovania, ktorý len poskytuje kontextuálne informácie a odporúča akcie, ale nevykonáva ich autonómne. Celý proces zastrešujúci spracovanie, analýzu, dolovanie a nasadenie sa nazýva objavovanie znalostí.
Metodológia
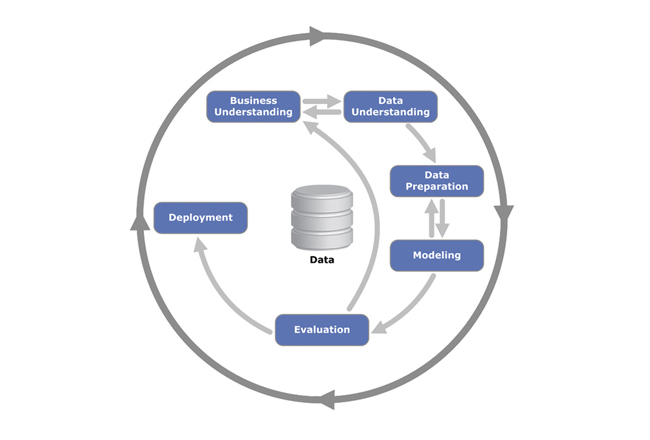
Najčastejšie používanou metodológiou na objavovanie znalostí je Cross-industry standard process for data mining známa pod skratkou CRISP-DM (obr. 20). CRISP-DM predstavuje iteratívny proces, ktorý nasadzuje znalosti do reálneho používania s ohľadom na cieľ a charakter dát. Prvou fázou je pochopenie cieľa, čo znamená, že je nutné špecifikovať a pochopiť, aká je úloha, ktorú chceme pomocou metód dolovania riešiť a zároveň špecifikovať jej typ. Predovšetkým teda či ide o klasifikáciu alebo predikciu. Klasifikácia „zatrieďuje“ príklady, resp. udalosti do konečného počtu vopred definovaných skupín, tzv. tried, ktoré majú svoje pomenovanie. Cieľový atribút je preto nominálny. Na druhej strane predikcia odhaduje hodnoty numerického atribútu v budúcnosti. Výsledkom by preto malo byť jednak určenie úlohy dolovania, jednak pochopenie problému príjemcu (zákazníka).
Pochopenie dát (data understanding)
Ide o druhú fázu metodológie CRISP-DM, v ktorej je úlohou pochopiť význam jednotlivých atribútov, analyzovať, v akom stave sa dáta nachádzajú, t. j. napr. aká je vzájomná vyváženosť početností jednotlivých klasifikačných tried (napr. pomocou histogramu), určiť štatistické rozdelenie atribútov, resp. vytvoriť kontingenčnú tabuľku či vykonať korelačnú analýzu. Základné metódy opisnej štatistiky nám môžu pomôcť lepšie pochopiť vzťahy medzi atribútmi a charakter skúmaných dát. Zároveň tak umožňujú odhaliť nechcené väzby, napr. v podobe dvoch a viac navzájom odvodených atribútov. Výsledkom je rozhodnutie, či sú dáta dostatočne dobré (objemom, vyváženosťou, úplnosťou atď.) na ďalšie odhalenie nutných krokov pri ich predspracovaní.
Príprava dát (data preparation)
Na základe informácií získaných z opisnej štatistiky vykonanej v predchádzajúcej fáze možno počas fázy prípravy dát realizovať ich úpravu do podoby vhodnej na modelovanie. Ide napríklad o generalizáciu a filtráciu atribútov, doplnenie (resp. odvodenie) chýbajúcich hodnôt, transformáciu a výber dát, vyvažovanie vzorky a pod. Príprava dát by spolu s ich pochopením mala zaberať väčšinu času pri objavovaní znalostí, nakoľko zlé pochopenie alebo nesprávne pripravené dáta do veľkej miery ovplyvňujú vhodnosť vstupu do fázy modelovania. Treba poznamenať, že príprava dát sa často vykonáva opakovane a obvykle prináša najväčšie rozdiely vo výsledkoch modelovania (pozitívne aj negatívne).
Modelovanie
Ide o fázu, kde sa na pripravené dáta aplikuje vybraný algoritmus alebo množina algoritmov dolovania. Pri štandardných algoritmoch prediktívneho dolovania ide o tzv. učenie s učiteľom, čo znamená, že sa celý dátový súbor delí na dve množiny (trénovaciu a testovaciu). Trénovacia množina je tvorená väčšinou 30 % záznamov (príkladov) z dátového súboru, ktoré zároveň obsahujú cieľový atribút a jeho hodnoty. Slúži na „trénovanie“ modelu, teda algoritmus si v nejakej podobe (napr. pravdepodobnostný strom, zoznam pravidiel) uchová vzťahy medzi cieľovým a ostatnými atribútmi. Obvykle je na tých istých dátach spustených viac rôznych modelov podľa charakteru dát, vyhodnotí sa úspešnosť a určí sa algoritmus, pomocou ktorého bol vytvorený najúspešnejší prediktívny model. Pri modelovaní môže dôjsť k tzv. preučeniu, čiže model je príliš fixovaný na dáta z trénovacej množiny. To znamená, že na testovacej množine dosahuje slabé výsledky. K preučeniu najčastejšie dochádza v prípade použitia trénovacej množiny s malým počtom príkladov, resp. pri priveľkom počte opakovaní cyklov učenia.
Vyhodnotenie
Testovacia množina na rozdiel od trénovacej slúži na vyhodnotenie procesu učenia, pretože neobsahuje cieľový atribút a jeho hodnoty. Úlohou natrénovaného modelu je predikovať výsledné hodnoty cieľového atribútu v trénovacej množine. Týmto spôsobom zistíme chybovosť modelu, pričom napr. pri binárnej klasifikácii vieme vyhodnotiť dva typy chýb: objekt patrí do triedy A, ale bol klasifikovaný do triedy B, objekt patrí do triedy B, ale bol klasifikovaný do triedy A. Podobne vieme vyhodnotiť aj správnosť modelu pre jednotlivé triedy, teda do akej miery je model schopný klasifikovať objekty triedy A a triedy B. V prípade predikcie počítame rozdiel – chybu odhadu od skutočného stavu rôznymi metrikami (najčastejšie stredná absolútna chyba – MAE alebo stredná absolútna percentuálna chyba – MAPE). Ak výsledky modelov nie sú postačujúce, treba sa znovu zamyslieť nad celým procesom od pochopenia a prehodnotiť predošlé prístupy a možnosti, ako spresniť model, ak je to možné.
Nasadenie
Pod nasadením rozumieme použitie modelu v reálnom systéme pri vykonávaní úloh. Ak model prestane plniť svoju úlohy, resp. jeho presnosť sa časom znižuje, treba ho pretrénovať, čo znamená zopakovať fázy modelu CRISP-DM. Nasadenie možno z hľadiska aktivity systému realizovať dvojako. Ako systém na podporu rozhodovania je úloha znalostí viac-menej pasívna, teda v podobe odporúčaní podporuje rozhodovací proces. Na druhej strane možno model nasadiť v aktívnej podobe, kde autonómne vykonáva akcie na základe výsledkov klasifikácie/predikcie.
Záver
V tomto článku sme opísali dôležitosť dát z pohľadu získavania nových znalostí. V kontexte metodológie CRISP-DM sme predstavili proces, ktorým dáta musia prejsť na to, aby bolo možné znalosti implementovať v podobe systémov na podporu rozhodovania alebo systémov, ktoré budú autonómne reagovať na rôzne udalosti. Práve senzorické dáta sú najčastejším zdrojom na získavanie znalostí.
Zdroje
[1] Babič, F. – Olejár, J. – Pella, Z. – Paralič, J.: Predictive and descriptive analysis for heart disease diagnosis. In: Annals of Computer Science and Information Systems: Federated Conference on Computer Science and Information Systems 2017. Varšava: Polskie Towarzystwo Informatyczne, 2017, vol. 11, p. 155 – 163. ISBN 978-83-946253-7-5.
[2] Sabanovic, S. – Majnaric Trtica, L. – Babič, F. – Vadovský, M. – Paralič, J. – Vcev, A. – Holzinger, A.: Metabolic syndrome in hypertensive women in the age of menopause: a case study on data from general practice electronic health records. In: BMC Medical Informatics and Decision Making, 2018, vol. 18, no. 1, p. 1 – 24. ISSN 1472-6947.
[3] Muchová, M.: Data analysis in logistics company. In: SCYR 2018. Košice: TU 2018, s. 73 – 74. ISBN 978-80-553-2972-7.
[4] Sarnovský, M. – Bednár, P.: Projekt MONSOON – návrh platformy pre analýzu veľkých dát v priemysle. In: Data a znalosti. Plzeň: Západočeská univerzita v Plzni 2017, s. 93 – 97. ISBN 978-80-261-0720-0.
Poďakovanie
Táto séria článkov vznikla vďaka realizácii projektov podporených Kultúrno-edukačnou grantovou agentúrou Ministerstva školstva, vedy, výskumu a športu SR a Slovenskej akadémie vied pod číslom 05TUKE-4/2017 a Agentúrou na podporu výskumu a vývoja na základe zmluvy č. APVV-16-0213.
Ing. Pavol Šatala
pavol.satala@tuke.sk
Ing. Vladimír Gašpar, PhD.
vladimir.gaspar@tuke.sk
doc. Ing. Peter Butka, PhD.
peter.butka@tuke.sk
Technická Univerzita v Košiciach
Fakulta elektrotechniky a informatiky
Katedra kybernetiky a umelej inteligencie – Oddelenie hospodárskej informatiky
Laboratórium chytrých technológií
Vysokoškolská 4, 042 00 Košice
http://kkui.fei.tuke.sk/chi/smart










